MySQL随笔 - 磁盘数据结构
接着上一章,这篇简单介绍一下InnoDB存储引擎磁盘中存储的数据结构。
索引
MySQL最经典的数据结构,索引又分为聚集索引和二级索引。聚集索引一般是由表的主键构成的,主键的唯一性保证了聚集索引的唯一性。对于聚集索引,它和二级索引最重要的区别是聚集索引是可以直接访问到对应的磁盘数据页的,但是二级索引不存储数据,它只存储主键,这样在二级索引查到后,需要再到聚集索引中拿对应的数据。
对于MySQL的索引来说,它采用了B+树的实现方式。我们只有在叶子节点才能拿到对应数据存储的位置。并且叶子节点采用了链表的数据结构,可以方便的访问到下一个和前一个数据。B+树还是一个自平衡二叉树,这意味着它的左右节点的高度是相同的,如下图所示:
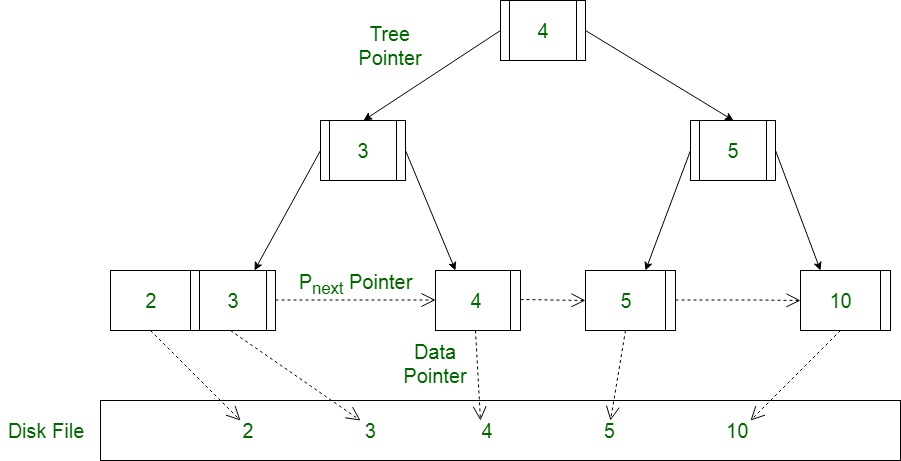
采用这种方式的好处是,这会大大减少磁盘I/O,因为对于这种数据结构,层高越高,它所产生的磁盘I/O次数越多。而MongoDB则采用的是B-tree的数据结构存储数据,这是MongoDB是一个nosql数据库,它摆脱了关系型数据库的限制。单点查询更适合它,所以采用B-tree拿到数据即可返回,而不需要走到叶子节点。这样保证了它的效率会小于O(n)。
Doublewrite Buffer
这个磁盘数据结构看起来比较陌生,其实这就是一个buffer pool的磁盘备份。在MySQL宕机发生时,它可以从这里快速的恢复内存中的数据。
Redo Log
Redo Log的作用可以从它的字面意思理解,这个Log的作用就是Redo,即在MySQL宕机后,对一些还没做完的事务的数据做修复。只有修复完后,MySQL才会对外提供正常服务(在Go语言中这属于程序的init操作)。Redo Log里存储的主要是修改产生影响的记录的编码。
Undo Log
Undo Log,顾名思义就是将已做完的恢复成undo的样子。一条Undo Log记录的就是如何通过一次对聚集索引的事务操作将数据恢复原样。当某些隔离级别看不到其他事务作出的修改时,就会访问Undo Log来获取原始数据。
Undo Log不需要被Redo Log记录,它只在需要回滚操作时被用到。由于它对事务不可或缺,所以它的最大记录条数也就恰恰限制了MySQL所同时执行的事务条数。
总结
我们现在总体看一下InnoDB的架构设计:
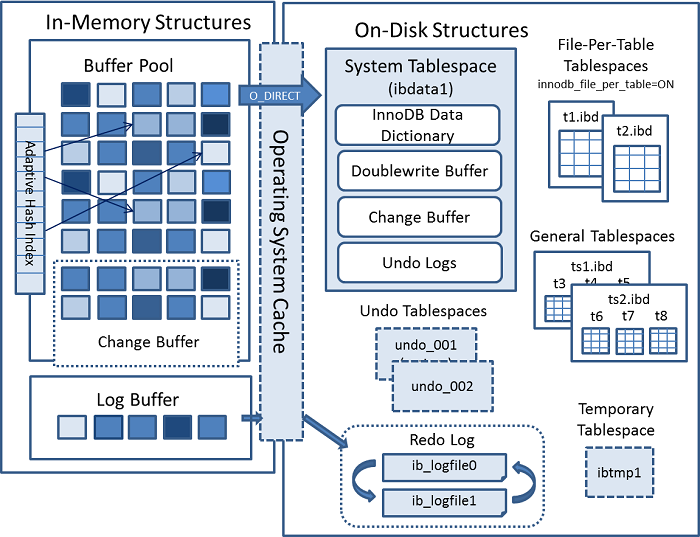
内存侧主要是我们前面讲的 新老数据的LRU Cache设计,并附带了一些hash索引、change buffer、log buffer等。磁盘侧数据主要以B+树这种数据结构为主,加速磁盘访问的速度,同时包含redo log 和 undo log来对MySQL的性能和事务原子性做保障。