MySQL随笔 - 总结
在前面的随笔中,我们分析了MySQL的许多重要的部分,如:索引、buffer pool、redo log、undo log等。这些都是MySQL中非常重要的组成部分。当然,MySQL是个非常复杂且精巧的数据库,它包含很多软件的设计哲学和算法思想。非几篇文章可以讲完,所以我只能摘一些部分做简要概述,无法面面俱到。本章我们主要将前面的知识碎片串联起来,尽量将MySQL的大的轮廓描绘出来。
整体架构设计
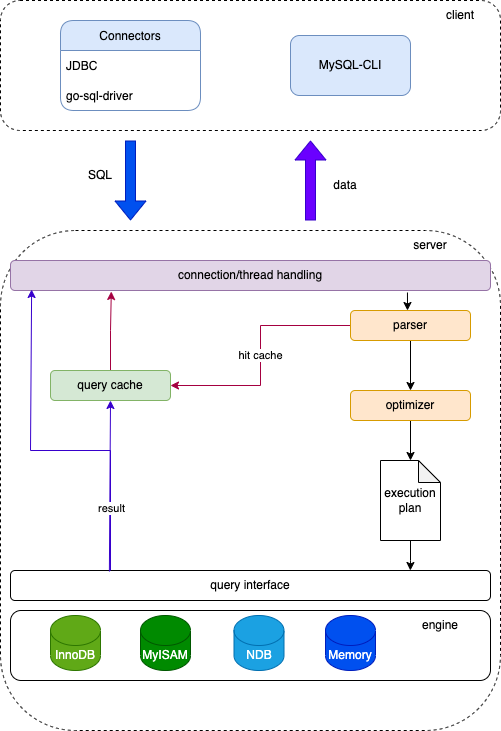
这里简单画了一下大致的架构图,这里仅仅是MySQL系统层面的,当我们的请求从各种客户端发来的时候,我们的MySQL进程会为该请求分配一个线程。因为MySQL是一个单进程多线程的程序,所以它可以并发的处理请求。
在线程拿到SQL后,需要使用解析器对SQL进行解析,如果发现缓存里有对应数据,则拿缓存,否则将使用优化器(使用索引)来查询对应的磁盘数据。
这里省略了一个部分,就是所有引擎都存在的bin log部分,由于这个和事务关联性比较大,所以我想拿到下面👇和redo log做一个比较。
InnoDB架构设计
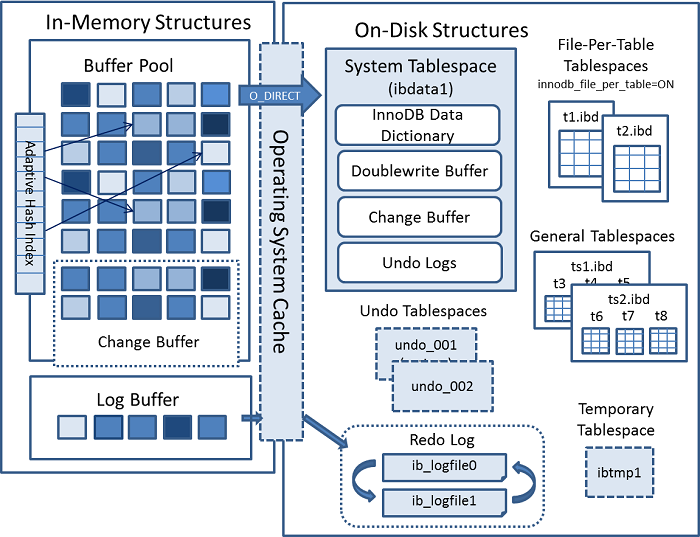
这张图在前面的文章中总结内存和磁盘数据结构时也有拿出来讲过。我们这里再做一次总结型的概述。
承接上面的SQL请求,当我们在执行完SQL的优化后,下一步就是来存储引擎拿数据了。如果是个读请求,那么我们这里的操作会很简单,因为读本质不需要我们做太多事务特性的保证,所以我们先来假设它是个写请求。
我们将单个写请求放到事务中思考,在前面我们也说过,写入请求时,会将其写入buffer pool的log buffer 中,并在随后将对应的数据刷入磁盘。那么这里会有一个疑问:bin log是在此步之前还是之后,又如何保证两个log的一致性呢?
2PC
实际上,由于MySQL内部对于多个存储引擎而言(如多个InnoDB而言),他们之间的数据是不可见的,所以MySQL本身采用了2PC来实现数据的一致性保证。也就是第一步它会先发起投票,如果多数投yes那么事务将会被应用。
当事务被提交时,首先 MYSQL_BIN_LOG::prepare会被调用,这时MySQL将会通知innodb产生一次投票,然后执行innobase_xa_prepare,这就是上面说的变动将被写入log buffer后刷入redo log。当此时,innodb会认为数据已经prepared了,但是还没有提交。如果此时发生了crash数据将会被回滚。
一旦所有的存储引擎都回答yes,那么此时MYSQL_BIN_LOG::commit将会被调用,数据将会被记录到binlog。最后将会调用innobase_commit将数据刷入redo log。
回到上面的疑问,第一点,写入顺序是先binlog后redo log。第二点,一致性的保证主要是靠2PC保证。那么如果在innobase_commit前crash掉,会发生什么呢?答案是:MySQL将会启动备案来确认binlog是否被安全的关闭,在这种情况下自然是:没有!所以此时对于所有没执行该事务的存储引擎,他会让他们去把这个事务执行掉。 这也解释了上面的binlog为什么属于非存储引擎层面的设计。
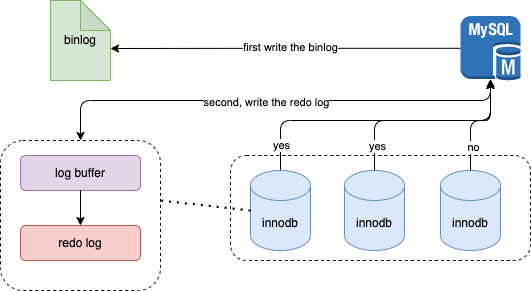
诸如undo log、double write buffer这些已在前面章节介绍过,所以这里不再赘述。
索引
上面我们主要介绍了数据变动的一致性保证,现在我们回头来关注查询。我们知道,如果一个查询没有用上任何索引,那么这将是一个灾难性的查询,因为这将扫描所有的数据行,具体的可以用explain语句来看是否用到索引,这块稍后再讲,我们先来看索引的设计。
索引设计
在前面的章节,我们使用了B-Tree介绍了索引,但是讲的不够透彻,我们再来复习一下。假设我们有一张表:
create table `student`(
name varchar(24) not null default '' comment '姓名',
sex int(11) not null default 0 comment '性别 0: man 1:women',
class varchar(24) not null default '' comment '班级',
primary key(`name`),
) engine = innodb;
如果我们插入以下数据:
| name | sex | class |
|---|---|---|
| michael | 0 | 1 |
| Peter | 0 | 1 |
| Mia | 1 | 2 |
| Judy | 1 | 3 |
| Sandy | 1 | 1 |
由于name索引是顺序的,所以我们会得到如下结果:
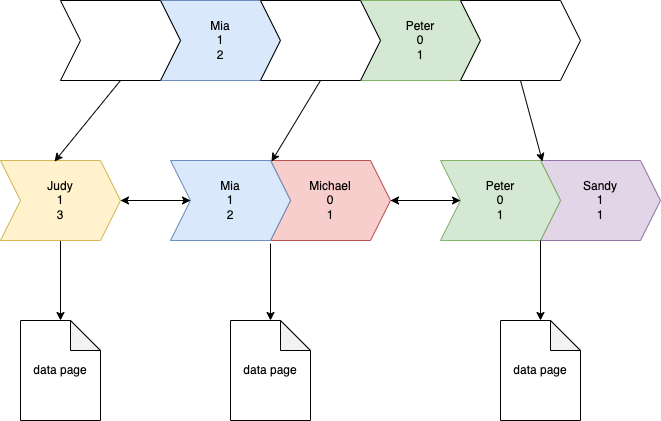
这是一颗简单的b+树,innodb采用这种结构来减少磁盘的i/o。通过观察这颗树我们可以看到,每个节点的左指针会指向小于它的记录,而每个节点的右指针会指向大于等于它的记录。
当我们查询一条单行记录时,如果使用到了二级索引,它会自顶向下遍历找到所有符合该查询条件的二级索引,然后去聚簇索引中拿对应的数据。当然,此步骤在覆盖索引时会被跳过,当二级索引中的数据已经可以满足查询需求时,比如你查询的字段只包括该二级索引所覆盖的字段。
当我们找到对应的b+树的叶子节点时,如果是范围查询,此时就可以使用底层链表所带来的顺序读写的能力遍历出需要的数据范围。
另外,由于聚簇索引在使用时会经常被用到,所以建议是使用短而小的字段来做主键。当然,如果没有指定主键,MySQL会创建一个隐藏的字段作为主键。
索引失效问题
由于索引的组织是有序的,通常我们可以采用二分查找来寻找对应的数据和数据范围。这也是为什么前缀匹配可以利用索引而非前缀匹配的模糊查询不行。比如:
select * from student = 'mich%';
就可以利用索引。
当创建联合索引时,比如字段a,b,c是一组联合索引,此时如果b使用了模糊查询,此时后面的c将无法使用索引。具体的,MySQL会将符合a以及模糊b的所有二级索引查出来,然后根据筛选条件过滤掉不需要的行再去聚簇索引中获取对应的数据。这种规则通常被称为最左前缀规则。
SQL执行计划
一个查询语句是否用到索引,通常我们会使用explain来看他对应返回的结果。如果一条查询没有用到任何索引,那么它将会扫描全表,此时explain会返回如下结果:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | a | ALL | NULL | NULL | NULL | NULL | 61397 |
范围查询
explain select * from a where a.uid = 8 or a.uid=7381;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | a | range | uid | uid | 514 | NULL | 2 | Using index condition; Using where |
由于我们在uid上建立了索引,所以此时会使用到索引。这里Using index condition代表数据是被执行了一遍Index Condition Pushdown(ICP)的,因为范围查询使用不了索引,所以这里为了避免全表扫描,这里使用index condition来筛除不符合查询条件的二级索引,这样在回到聚簇索引上时,减少了数据量。
覆盖索引
explain select id from a where id = 1;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | a | const | id | id | 514 | const | 1 | Using index |
Using index代表了所有的数据只从索引中获得。